Aggregation is the feature that allows DTS to seamlessly unify resources from disparate data sources based on predefined relationships and present them for consumption via Streams.
The configuration unit (project artifact) for Aggregation is called an Aggregate (stored in the AGGREGATE collection). Multiple Aggregates can be defined for any DTS project using the Aggregates Page in the Web UI.
The DTS component responsible for resolving aggregate data requests is called an Aggregator.
Aggregate Elements
Each well-defined Aggregate must contain the following elements:
Main Source |
The starting point for the Aggregate. The main stream will be created on this data source and its results will be the root for requesting data from the secondary sources. |
Secondary Sources |
The other data sources for the Aggregate. Queries performed on these sources depend on results from their parent sources (as defined through the Relationships). |
Relationships |
Simple clauses that define equality relationships between parent and child sources. Each is modeled by feeding the value of an attribute from a parent's result as the value of another attribute in a child's query. |
Filters |
Each source (main or secondary) can have a fundamental filter. •On Main Sources, the filter will restrict what base records will pass through to those matching the filter. •On Secondary Collection Sources, the filter will inject static/constant parameters in the queries used to find data pertaining to an aggregate record, with the Relationships providing the variable parameters. •On Secondary Routine Sources, the filter is used to set constant values for routine inputs. |
Each source has a list of Attributes (items which can be included in the Aggregate result) and Query Parameters (items which can be used to create relationship queries targeting the respective source).
![]() Sources can be Collections or Routines.
Sources can be Collections or Routines.
Collection have their fields serve as both Attributes and Query Parameters.
Routines have their inputs (arguments) serve as Query Parameters and their outputs (results) serve as Attributes.
![]() Each source (main or secondary) can also have a fundamental filter defined, which will restrict results from that source to the ones that match the filter.
Each source (main or secondary) can also have a fundamental filter defined, which will restrict results from that source to the ones that match the filter.
![]() The list of Attributes from each source that will be included in the aggregation process is fully customizable, as are the names with which the respective attributes will be tagged in the resulting records.
The list of Attributes from each source that will be included in the aggregation process is fully customizable, as are the names with which the respective attributes will be tagged in the resulting records.
![]() It falls to the user to ensure that no two Attributes across an Aggregate have the same name. The name customization feature mentioned above must be used when duplicate Attribute names are present.
It falls to the user to ensure that no two Attributes across an Aggregate have the same name. The name customization feature mentioned above must be used when duplicate Attribute names are present.
Rules and Limitations
The following set of rules governs how aggregates function and it is not expected to change:
•Only Sources that have been included in the project are available for use in Aggregates. For Collection Sources, only the fields that are included in the project will be available for use in Aggregates.
•Each Secondary Source must have at least one relationship. Secondary Sources without relationships are ignored.
•Only the Attributes from a parent source that have been included in the Aggregate are available for relationships with child sources.
•All Query Parameters from a child source can be used in its relationships, regardless of their inclusion status in the aggregate.
•Circular references cannot be created using Aggregate Relationships.
The following set of limitations exists for the current version, but is subject to possible changes in future releases:
•The Main Source of an Aggregate must be a Collection.
•Secondary Sources cannot be Routines that return Streams.
•Only the Main Source's Query Parameters can be used to make queries on the Aggregate.
•All relationships are treated like "Outer Joins". If no results are found in a particular source for a particular query, the resulting aggregate record will still be delivered, but with the values for that source's attributes missing.
•If more than one result is generated by a particular relationship query, only the first record is used.
Example
Let's now look at an example Aggregate definition and see how it functions and what it outputs.
We'll assume we have a project with the following Sources included:
•A connector named ORACLE, with a CUSTOMERS table and a F_WEATHER_ZONE function;
•A connector named WEATHER_SERVICE with a AVERAGE_WEATHER function;
•A connector named MSSQL with two tables called METER_READS and METER_SPECS;
We'll also assume that all of the fields used in the Aggregate exist and have been included in the project.
Here is our Aggregate:
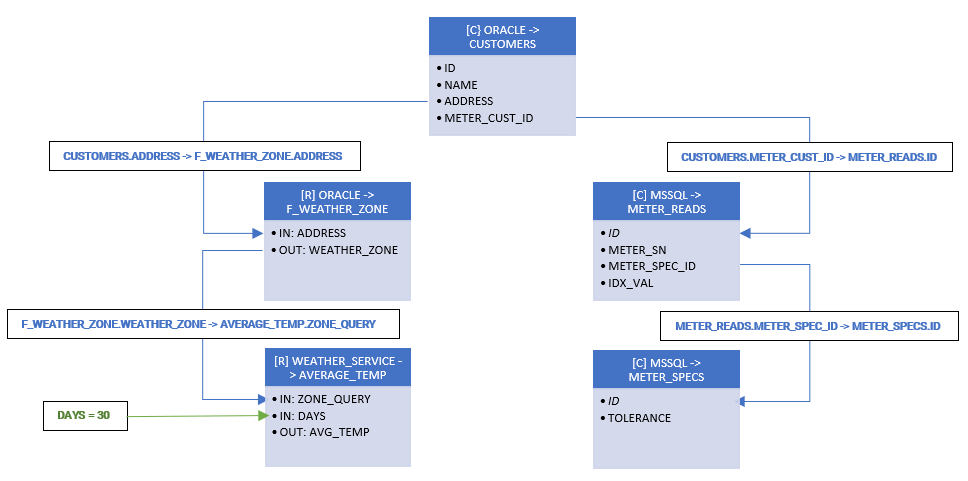
Let's do an inventory of the elements:
Role |
Element |
Type |
Details |
Main Source |
ORACLE -> CUSTOMERS |
Collection |
Our main source. A table of customers for our service. It contains data about the customers, including their addresses and the ids for their meters. |
Secondary Sources |
ORACLE -> F_WEATHER_ZONE |
Routine |
A stored function that creates a webservice-friendly weather zone query based on an address. |
WEATHER_SERVICE -> AVERAGE_TEMP |
Routine |
A webservice operation that returns the average temperature in a zone, over a number of days. We have a filter on it which serves to set a static value for the number of days parameter. |
|
MSSQL -> METER_READS |
Collection |
A table containing readings from meters.
|
|
MSSQL -> METER_SPECS |
Collection |
A table containing specifications for meters.
|
|
Relationships |
ADDRESS -> WEATHER_ZONE |
Routine Input |
A relationship that feeds a customer's address into the function that determines the respective weather zone. |
WEATHER_ZONE -> ZONE_QUERY |
Routine Input |
A relationship that feeds a weather zone into the web operation for the average temperature. |
|
CUST_ID -> ID |
Foreign Key |
A relationship modeling a Foreign Key for meter ids. |
|
METER_SPEC_ID -> ID |
Foreign Key |
A relationship modeling a Foreign Key for meter specification ids. |
Queries and responses on the aggregate will work the same as with any DTS collection, for example, for a particular CUSTOMER.ID (=123456), we would get a record of the form:
{
"ID": 123456,
"NAME": "Smith, John",
"ADDRESS": "1 Street Lane, Townsville, Countryland",
"METER_CUST_ID": 654321,
"WEATHER_ZONE": "townsville,co",
"AVG_TEMP": 301.4,
"METER_SN": 112233445566,
"METER_SPEC_ID": "acme-4",
"IDX_VAL": 9000.04,
"TOLERANCE": 0.03
}
The record will contain only the attributes we have included in the aggregate, all brought together in a single record and extracted based on our relationships, filters and query.